数据画布常见问题
Q:文件下载能力,已经生成的下载文件,刷新之后文件不见了?
A:文件生成后,因为(能力重启/画布重启/机器重启)数据易丢,请即刻下载存档。
Q:判定图如何批量导入知识?
A:有一个“批量添加判定图节点”能力,按照能力说明上传EXCEL即可批量添加知识。
Q:使用“全网历史判定图过滤”或“全网历史关键词过滤”能力后,数据未及时保存导致丢失,需要重新获取回溯后数据,怎么解决?使用“全网历史判定图过滤”或“全网历史关键词过滤”能力后,需要根据回溯结果进行后续操作(例如数据清洗,二次标引等)怎么处理?
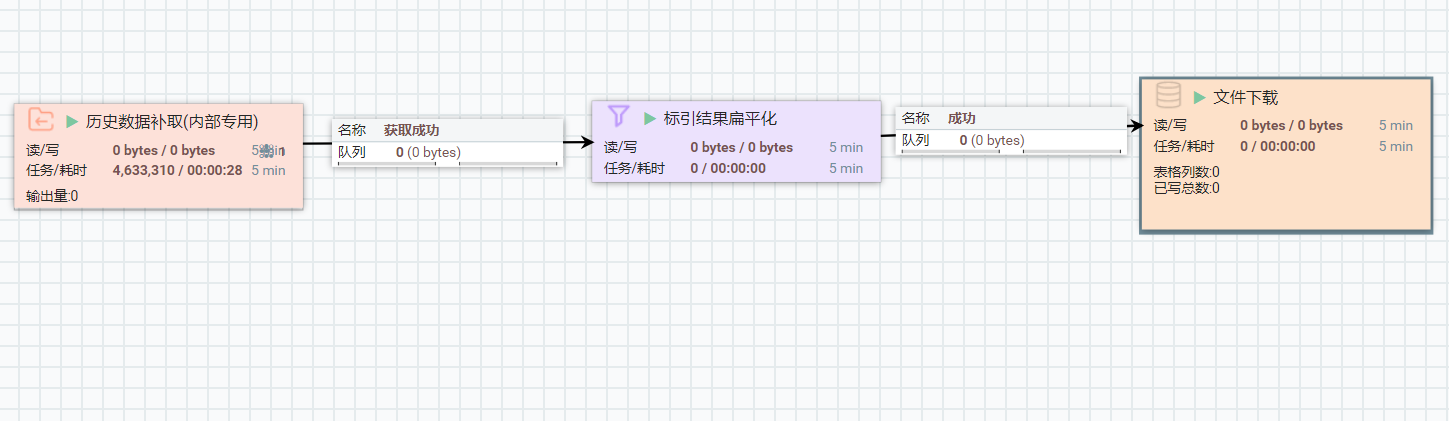
A:(1)将【数据导入】中的“全网历史判定图过滤”或“全网历史关键词过滤”拖入画布,将“文件下载”拖入画布右键单击能力,根据需求对能力进行配置,将能力进行连接,依次开启能力。
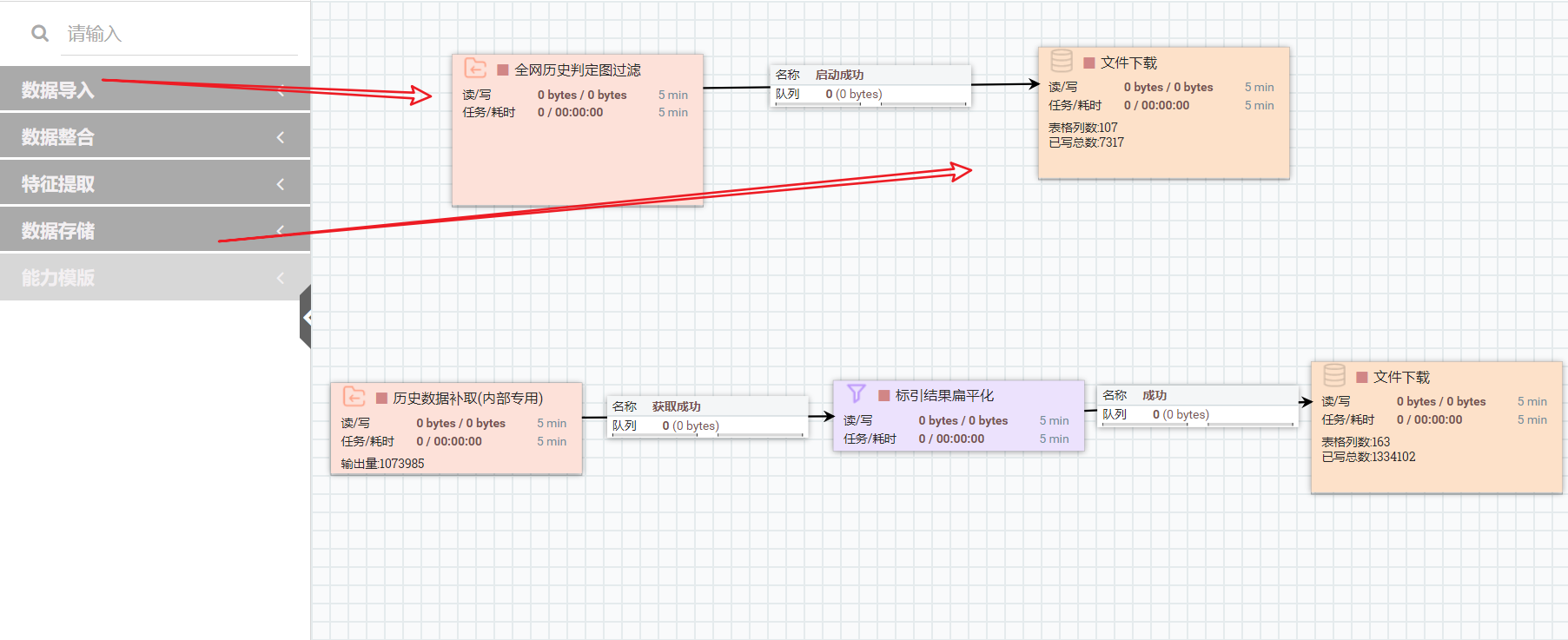
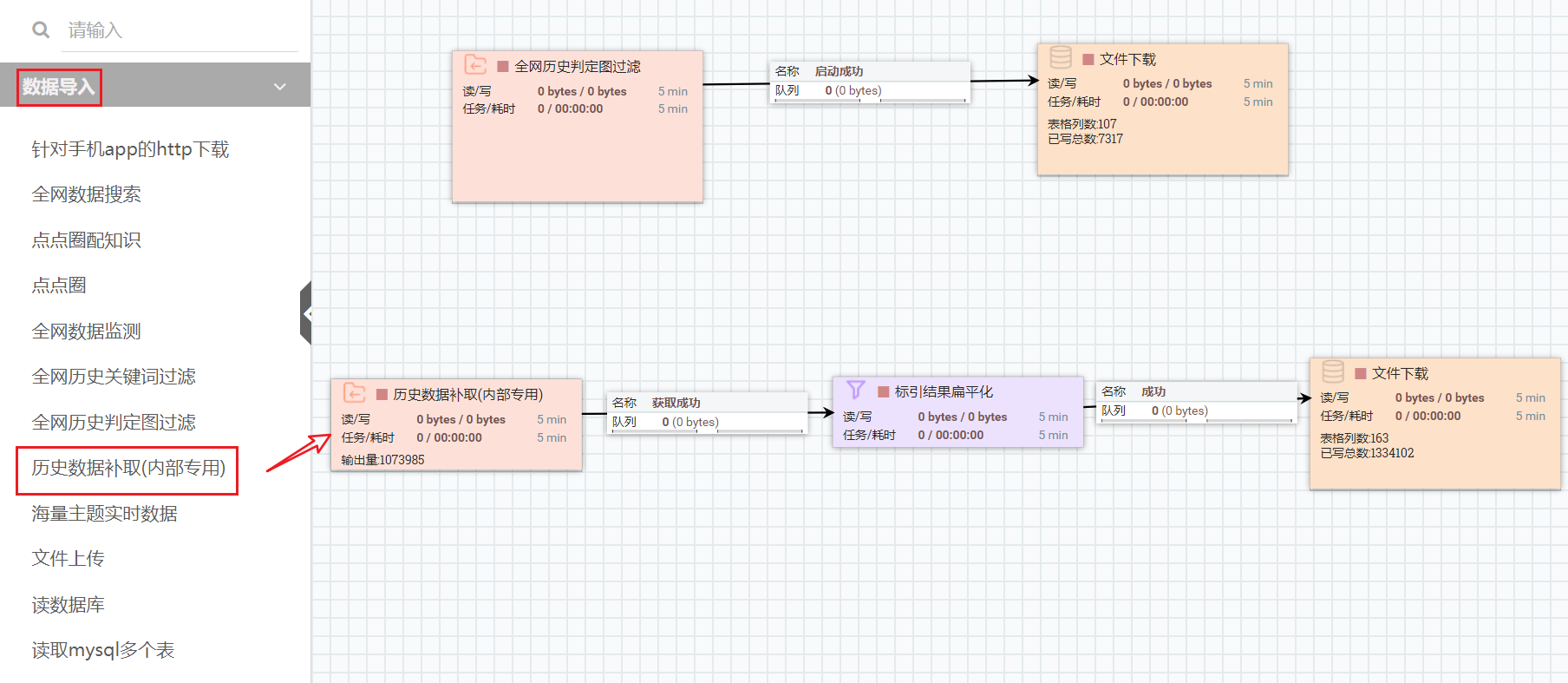
(2)在第一层能力完成,即首次回溯完成后,可利用能力“历史数据补取”进行数据获取或二次标引。将数据导入中的“历史数据补取”拖入画布,右键单击能力,根据需求对能力进行配置。(该能力是为"全网历史关键词"和"全网历史判定图"两个能力在成功跑完历史回溯后,由于画布空闲被释放等意外事件,造成没有取到历史数据的情况准备的)
订阅tag获取说明:
将“全网历史关键词”和“全网历史判定图”界面上的任务号记下来,到后台通过任务号查询到该任务的unique_tag(具体操作方法:瑞云平台 -> 数据标引 -> 数据中心工作流(正式)-> 搜索任务号,点击任务详情 -> 点击“任务desc”,在弹出的配置中,搜索“mapred.nifi.info.proc.unique_tag”,复制其中的值即可)
能力配置说明:
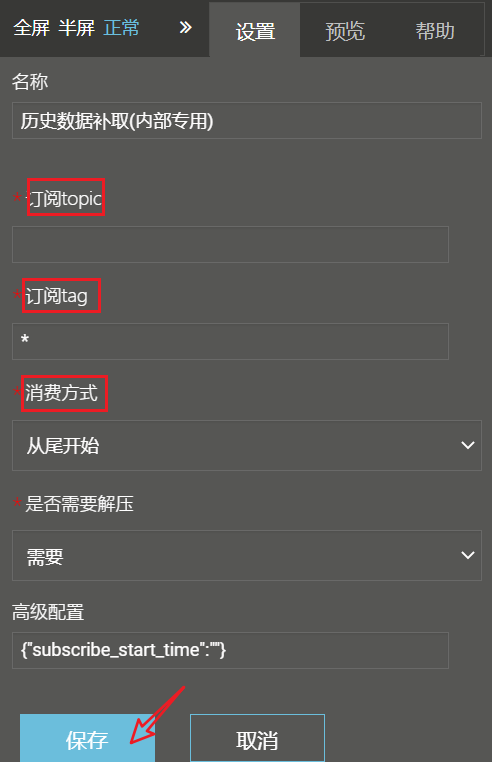
能力配置:订阅topic = LazyLableForNifi (写死)
能力配置:订阅tag=上一步得到的unique_tag
能力配置:消费方式
a. 从头开始(选取整个回溯任务的全部数据)
b. 从尾开始 (当任务尚未结束,从当前时间节点往后选取数据,即选取此时间节点以前的数据)
c. 从指定时间开始(估计一下之前历史任务的启动时间,能早几分钟别晚了,填入高级配置,例如 {"subscribe_start_time":"2020-01-01 12:13:14"})
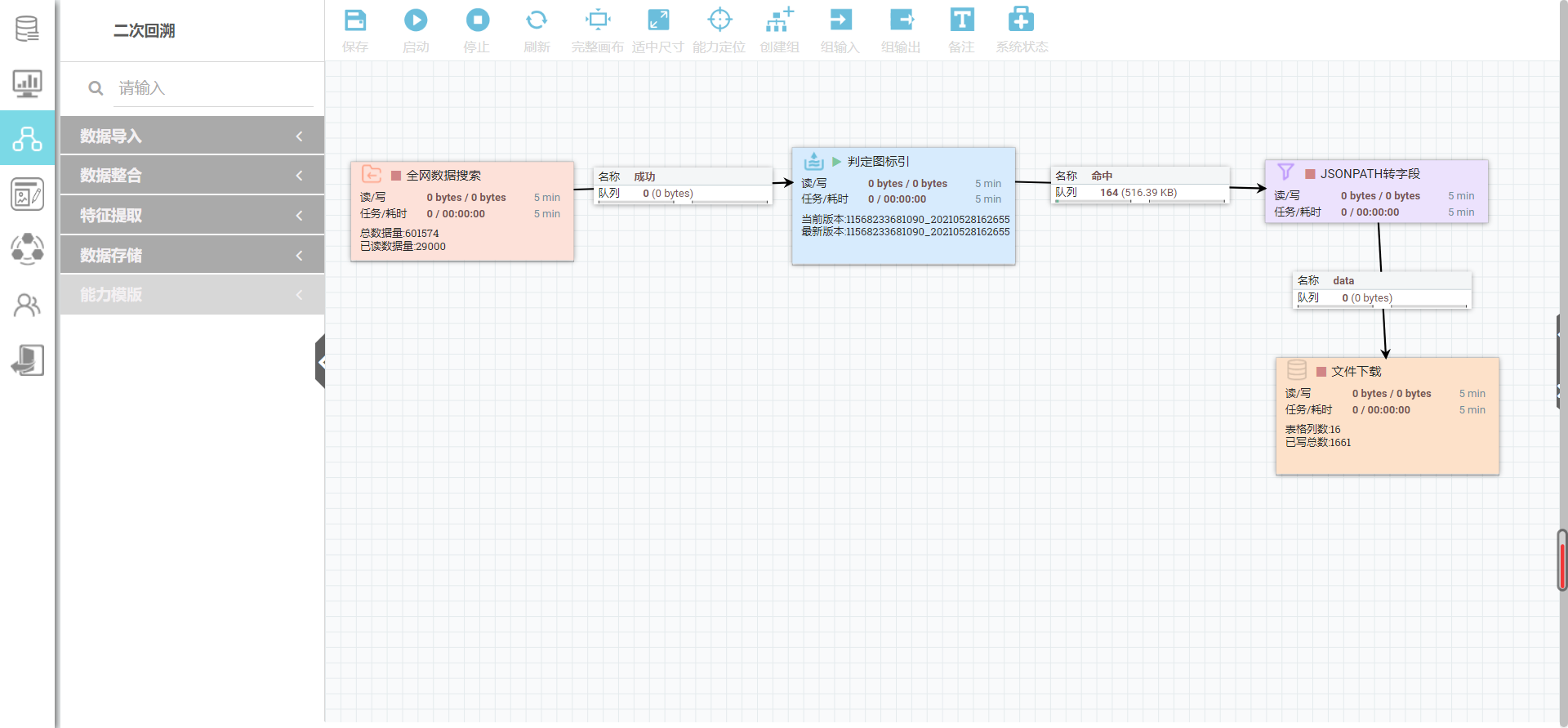
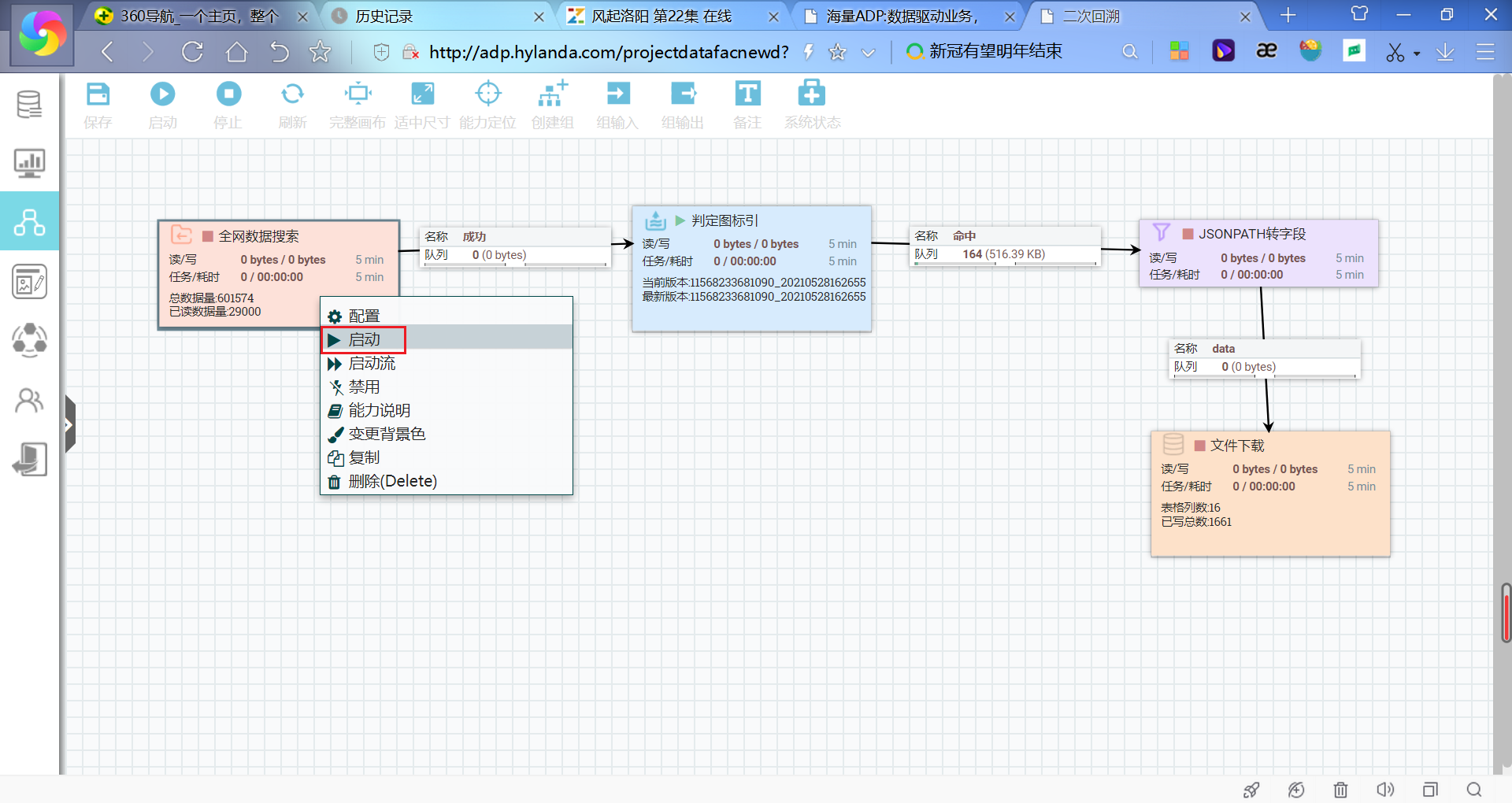
(3) 根据实际需要,将其余能力拖入画布中,依次进行能力的配置,如下图所示。
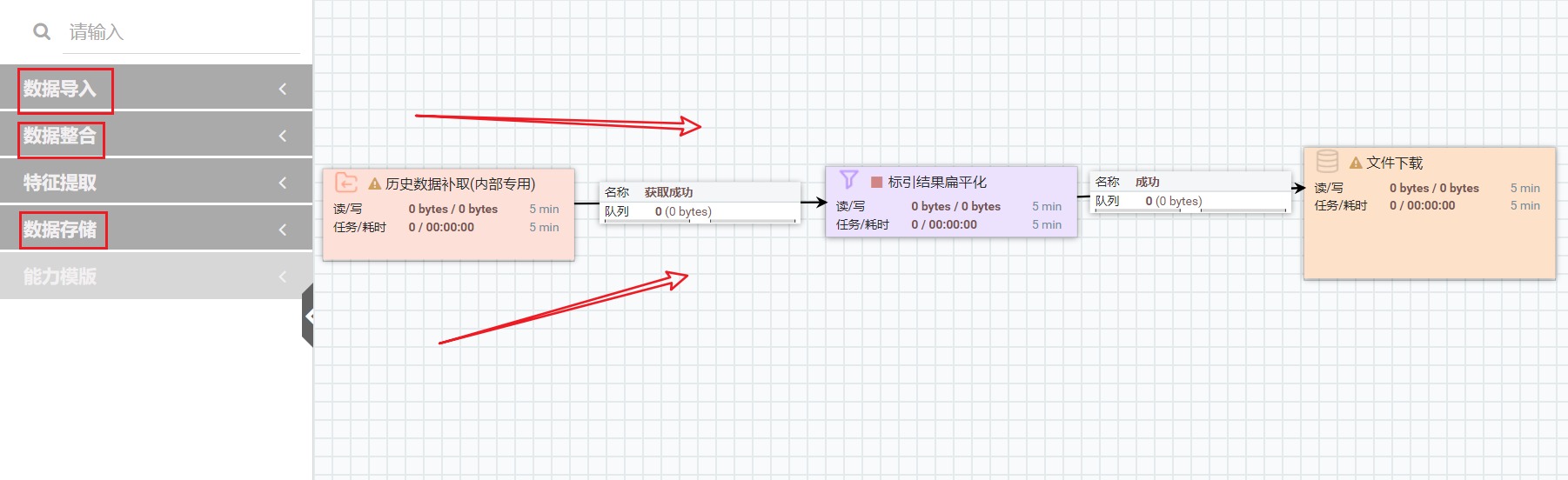
(4) 右键点击能力,在弹出的提示框中点击启动。依次启动能力。双击“文件下载”得到再次回溯后的数据。
Q:利用判定图给数据打标签后,不想进行标签拆分,只想将对应的标签内容输出,整体数据量保持不变,怎么做?
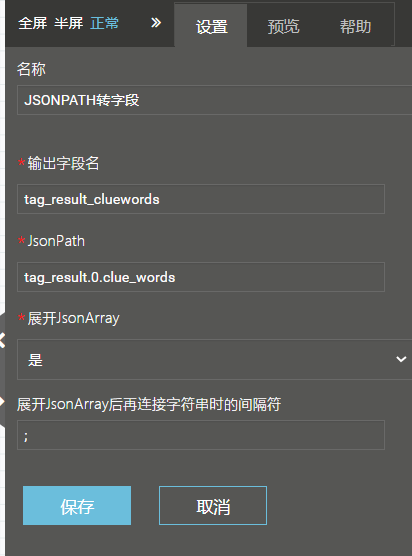
A:使用数据画布中“JSONPATH转字段”能力
(1)将能力拖拽至画布,并进行连接。
“判定图标引”能力后,连接【数据整合】中“JSONPATH”能力,然后接存储相关能力将数据进行保存。
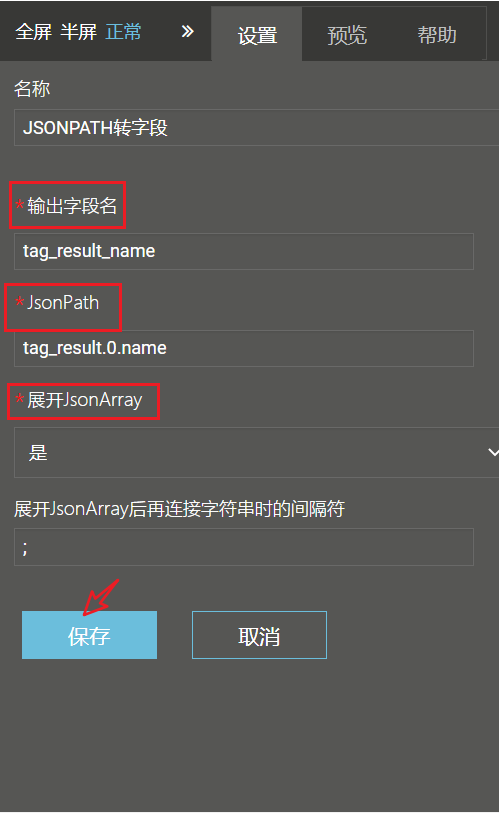
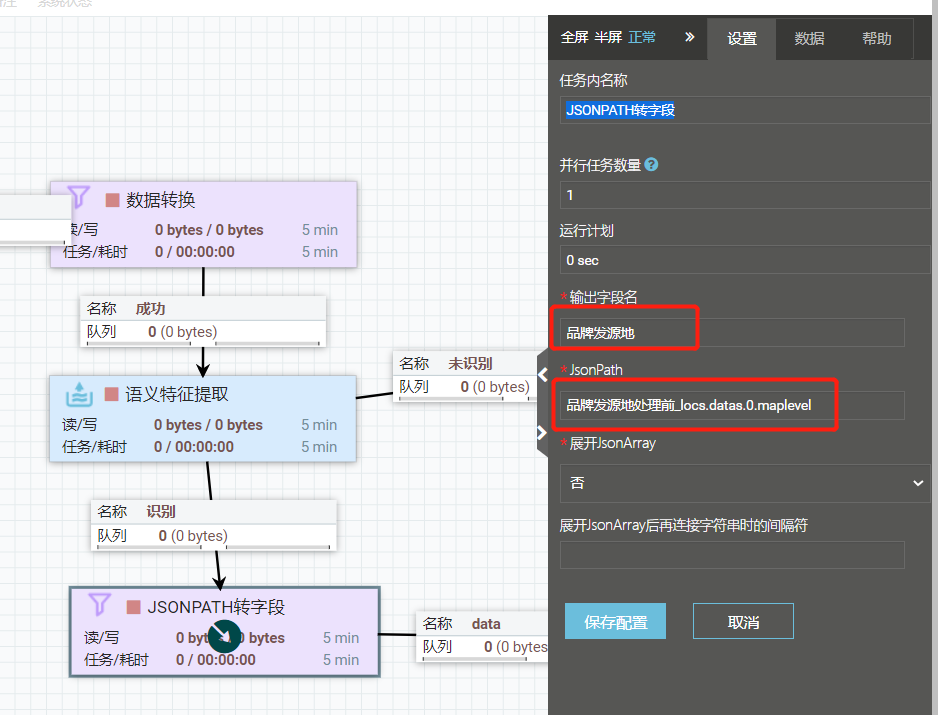
(2)JSONPATH转字段能力配置
在“输出字段名”配置项中,要写入数据的新字段名,例如可以给新字段起名为 “tag_result_name”。
在“JsonPath” 配置项中,填写要执行的jsonpath。若想获取标引后的标签内容,填写“tag_result.0.name”即可;若想获取标引后对应的关键词,填写“tag_result.0. clue_words”即可。
在“展开JsonArray”配置,含义为是否展开JSON数组,默认选择“是” (如果JsonPath有数组,则展开第一个 ".0." 的JsonArray,且字段名自动加 "_0,_1...")。
“展开JsonArray后再连接字符串时的间隔符” 配置,填入字符串连接符号,例如“ ;”。若不填则不连接字符串,若填了则不输出_0,_1等字段。
配置完成后,点击“保存”。
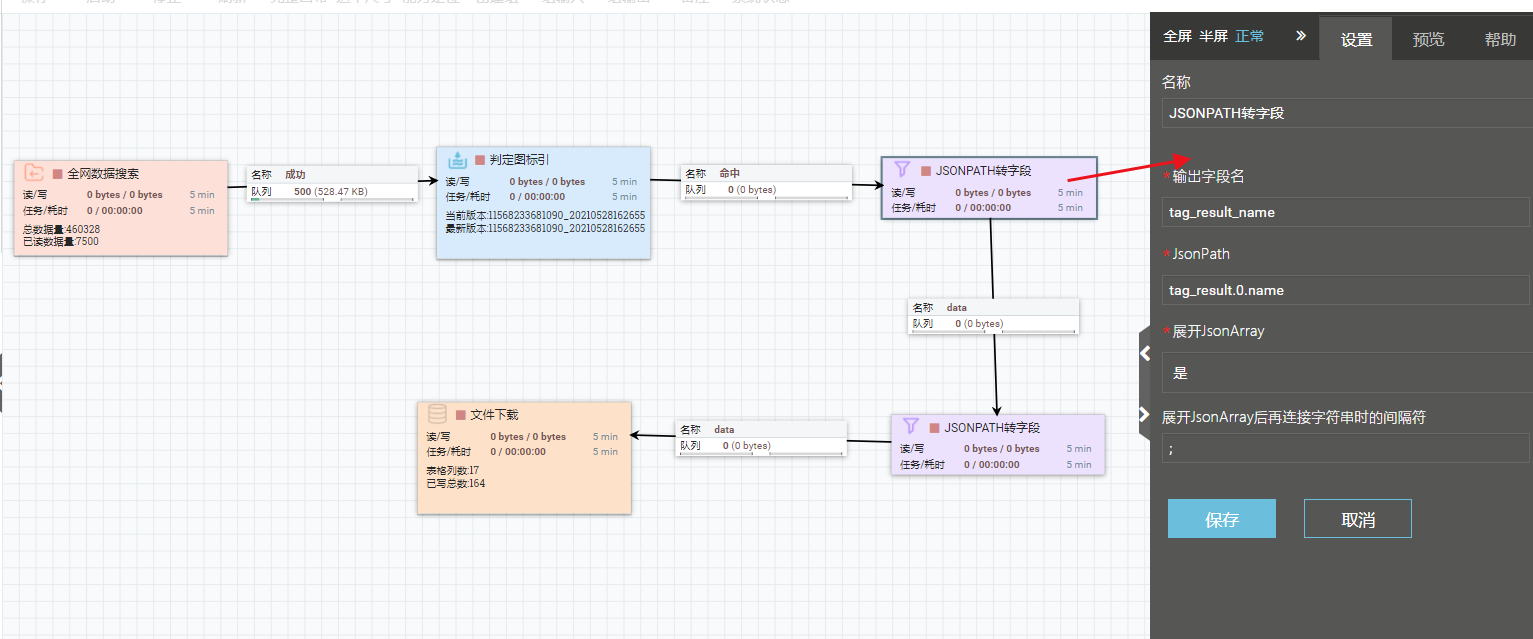
(3)若要同时提取tag_result中的多个字段(例如,同时提取name和clue_words),需链接多个JSONPATH转字段能力,针对不同字段单独配置。
(4)依次启动能力,执行完成后获取数据。
附:JsonPath基本用法学习地址: https://www.cnblogs.com/youring2/p/10942728.html
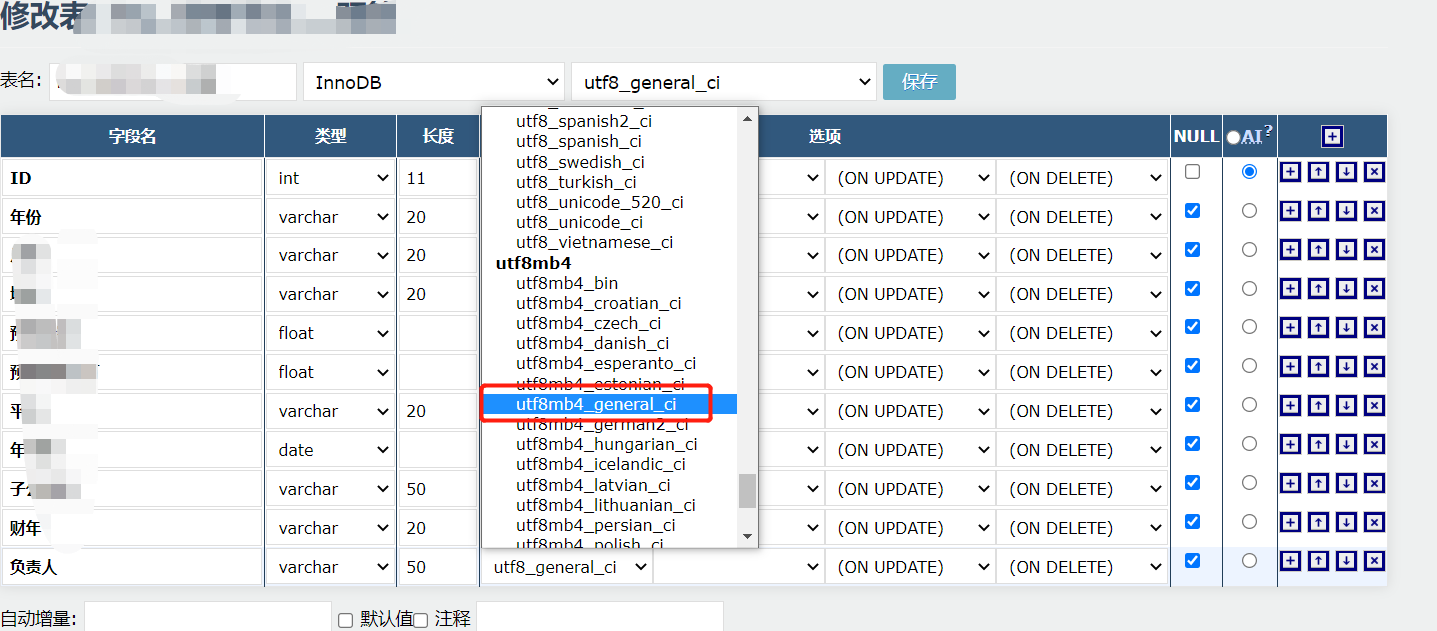
Q:数据的字段内容有表情符,导致入库失败,如何解决?
A:在数据库中修改表结构,将字段的字符集改为utf8m4_general_ci。报错信息如下:

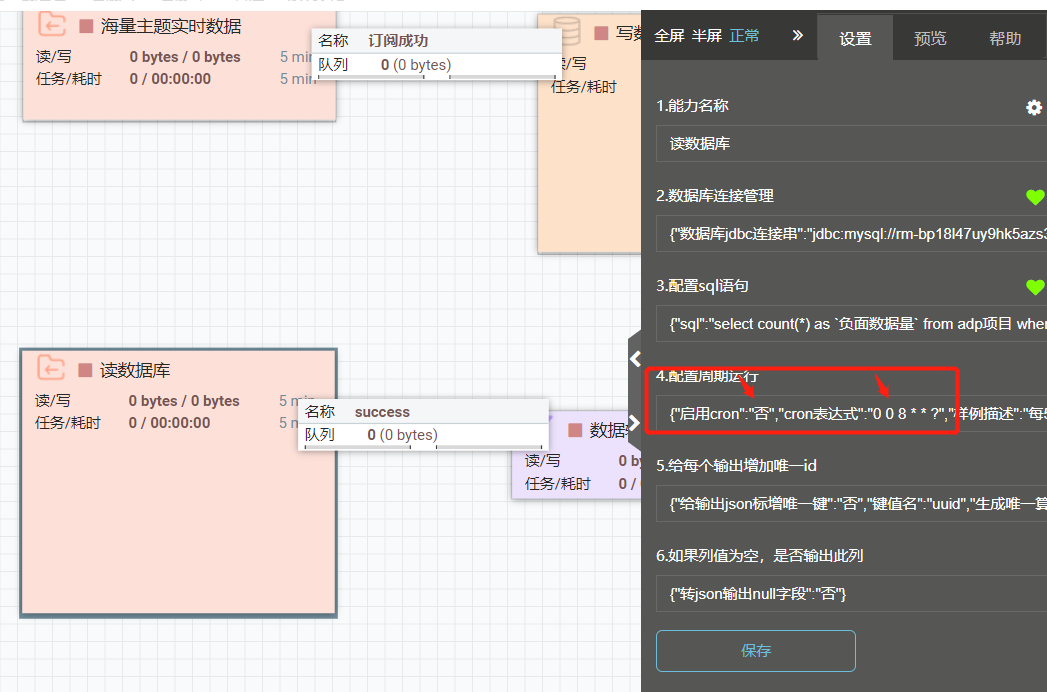
Q:怎样配置定时读数据云湖中数据库的信息?
A:使用“读数据库”能力,修改配置周期运行,只需要修改两部分,即“启用cron”改成“是”,配置“cron表达式”,
表达式的配置参考:https://cron.qqe2.com/
Q:什么能力能把指定字段按照一定的规则,拆分成新的字段?
A:用“数据转换”能力-字段分割,指定符号进行拆分。
Q:A项目的图表已做好,目前需要做一个B项目,A与B除了引用的数据表不一样,表结构相同,数据库相同,界面一样,功能都一样,如何快速复制?
A:画布上右键,数据源设置,可以一对一更换数据表,前提是两个表结构得一模一样。
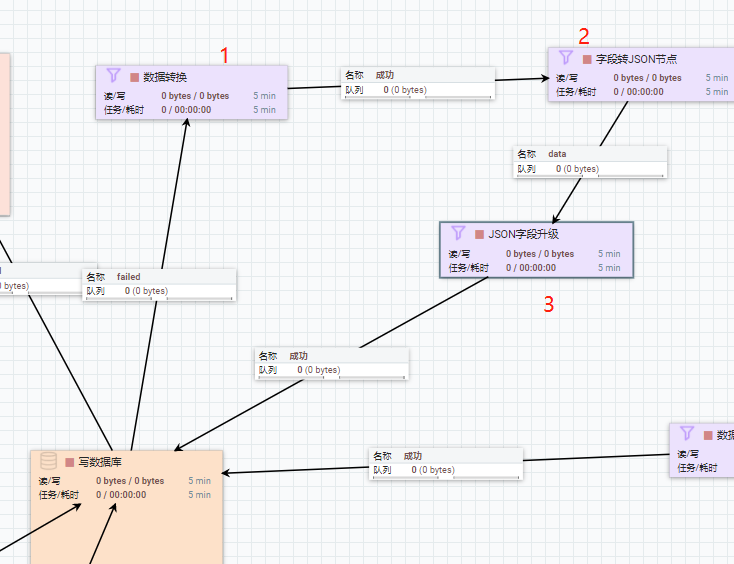
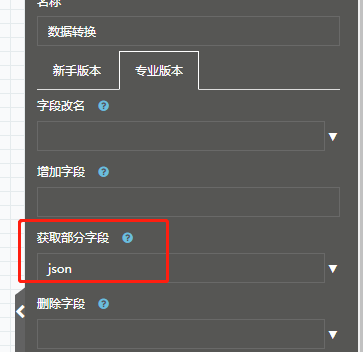
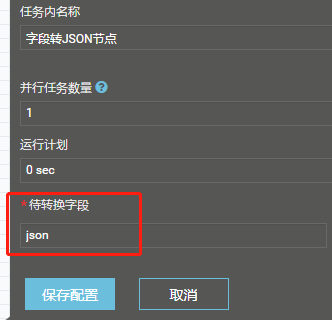
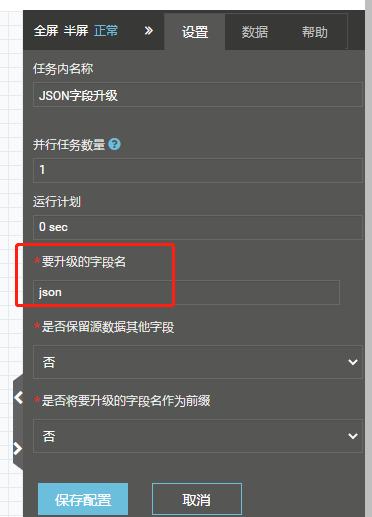
Q:写数据库能力,如果遇到长度失败的情况下,在调整好数据库里的字段长度后,如何将失败队列里的数据提出来重新入库?
A:总共3步骤,各自的配置如下。
Q:文件上传能力,日期格式的字段上传后显示内容被修改,如何解决?字段内容显示科学计数法的样式,如何解决?
A:把字段内容先存到一个文本编辑器里(例如:写字板),然后excel里的字段列全选,右键选择设置单元格格式,选择“文本”类型,然后再把内容复制回excel的对应位置中,然后再用文件上传能力。科学计数法的话,先将excel中整列改为数字型,不保留小数位,然后再用文件上传能力。
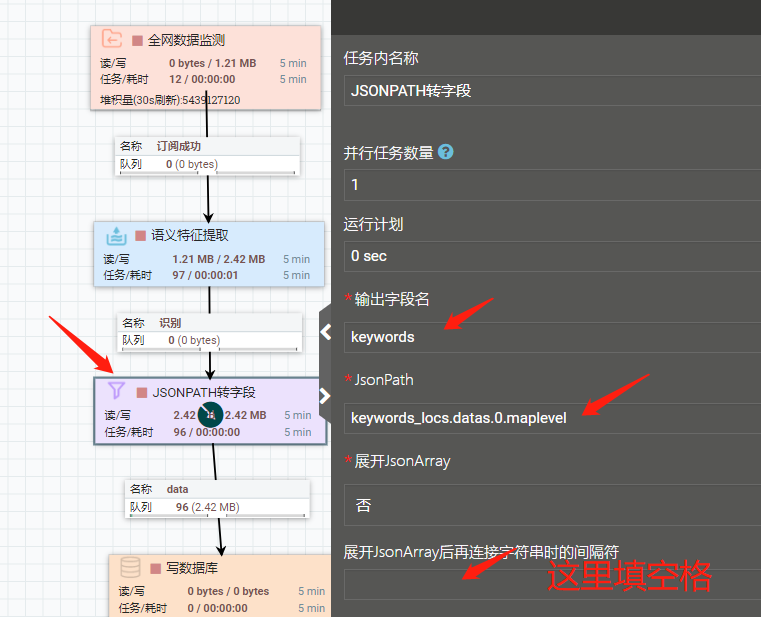
Q:如何进行数据的地区归一化(地名归一化/地域归一化)?
A:第一步:使用“语义特征提取”能力,配置如下:
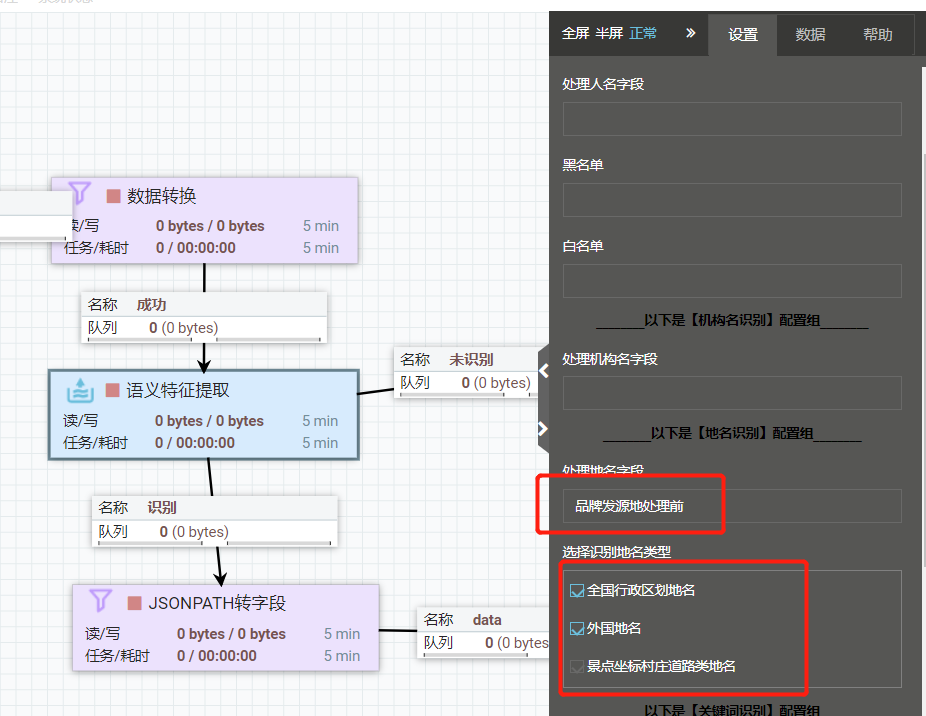
第二步:在“语义特征提取”后面添加“JSONPATH转字段”能力,填上输出字段名,填上Jsonpath,样例“上游数据需要归一化的字段名_locs.datas.0.maplevel”
配置如下:
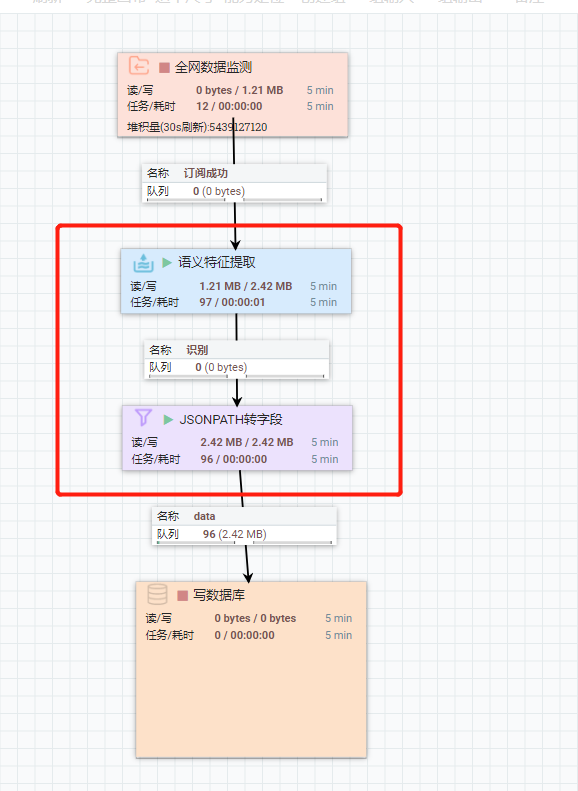
Q:如何进行数据的关键词提取?
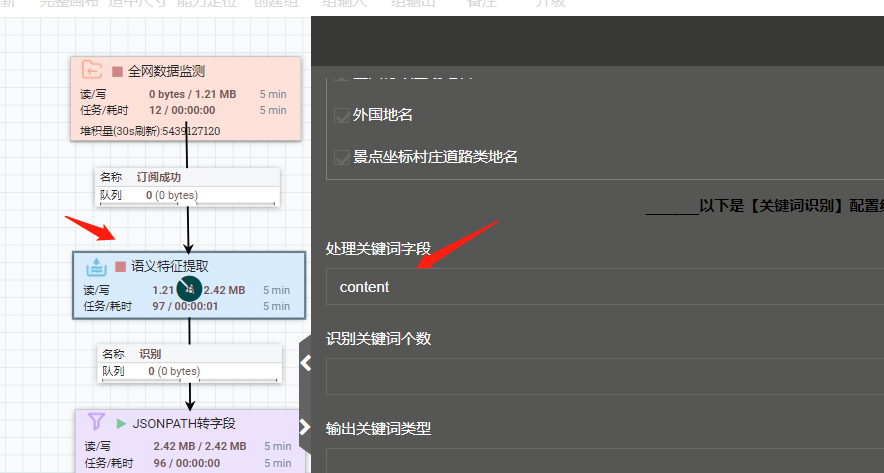
A:使用两个能力,语义特征提取+jsonpath转字段,“语义特征提取”后的关键词是json格式,用“jsonpath转字段”转成普通字段,配置如下:
1)2个能力如下:
2)语义特征提取:
3)JSONPATH转字段:
Q:数据画布左下角的机器性能指标如何判断是否机器正常运行?
A:数据画布左下角增加机器的CPU等机器指标,协助操作者及时了解机器运行状态,长期满负荷的情况下,建议做能力调整或升配处理。目前会显示三种颜色,50%以下是绿色-正常,50%-80%是黄色-提示;80%以上是红色-警告。
CPU-代表着机器的运行处理能力,在能力启动过多或能力的计算逻辑过于复杂的情况下会导致CPU升高,若在调整能力启动数和降低计算逻辑后,仍然不能降下来,可以给机器升CPU(核),升CPU可以加快能力的处理速度。
MEM-内存,代表着机器的运行处理能力,在能力启动过多或能力的计算逻辑过于复杂的情况下会导致内存升高,若在调整能力启动数和降低计算逻辑后,仍然不能降下来,可以给机器升内存(G),升内存可以加快能力的处理速度。 注:能力在启动时具体是消耗CPU还是内存是和能力的开发逻辑相关的,所以CPU和内存不一定都高。
DISK-磁盘,代表着机器的存储能力,升磁盘只能加大存储的空间大小,例如能力在运行时队列缓存容量,若队列已经被长期占满则或许会导致能力的运行问题,此时可以加大磁盘容量,增大队列的存储空间,但升磁盘不能解决能力的处理速度,只能降低由于堆积导致的异常。
问题没有解决?请留言提问